
Performance Analysis for a SQL Cluster
Posted: July 23, 2012 Filed under: SQL Server, Windows | Tags: analysis, cluster metrics, cluster performance, metrics, performance, performance analysis, sql, sql cluster, sql cluster metrics, sql cluster performance, sql metrics, sql performance 5 CommentsI was recently asked to pull the performance metrics for a new SQL cluster at work. In an effort to finally get back to blogging, I thought I’d share my results and how someone else may be able to look at their clusters for ways to improve. I should start by saying that although this analysis was performed on a two-node Windows Server Failover Cluster using Windows Server 2008 R2 x64 (WSFC, formerly MSCS) and SQL Server 2008, SQL-specific metrics are not pulled. Rather, I looked at the Big Four: CPU, Memory, Disk, and Network. The second node in the cluster, Node B, was analyzed because the application using the first node was not in production yet, so we knew that node would barely be utilized.
Using Microsoft System Center Operations Manager (a behemoth in its own right!), I was able to pull the previous six days’ worth of performance data. What I included in my analysis were graphs of performance for seven days, an explanation of what the data was measuring, and somewhat of an average baseline against which to measure.
The original work was presented in PowerPoint. I’ve taken screenshots of the presentation and included them here.
Metrics
-
Processor
- % Processor – avg. % busy time
- Processor Queue Length – # of threads waiting to execute
-
Memory
- Memory Available (MB) – amount of memory available
- Memory Used (%) – amount of memory used
- Pages/Sec – number of hard page faults
-
Disk
- Current Disk Queue Length – number of R/W waiting
- Avg. Disk sec/Transfer – avg. length of time per R/W
-
Network
- Output Queue Length – # of packets queued
CPU Performance

40% was chosen as the average processor time which one would want to stay below because it’s a two-node cluster. Taking the failover capacity into consideration, if both nodes were running at 40% on average, during a failover, a single node would then run at about 80%, leaving some room for peaks and not bogging down the sole remaining SQL server.
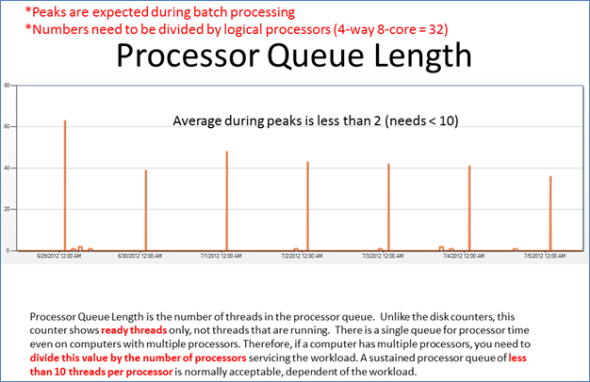
The peaks seen in the graph of Processor Queue Length are occurring because of nightly backups. This type of response is understandable. Some backups were running concurrently, though, and were subsequently re-scheduled in order to stagger the load seen by the processor. The processor wasn’t maxing out during these backups, but we could at least diminish the peak for better performance. Note that Processor Queue Length is actually measured per processor actually servicing the workload. So depending on how many cores this particular SQL server is using during backups, we need to divide the Processor Queue Length seen above by that number.
Memory Performance

This server, which is Node B in the cluster, is actually configured with 384 GB of usable RAM because memory sparing is enabled. As we’ll see below, relatively little memory has been in use the past seven days.

As we can see in the Memory Used graph, only about 15% of RAM is in use. This is about 57 GB. Obviously the SQL instances on this node are quite busy, but we can see that at least so far, not much of the Node B capacity has been used. Because it’s a two-node cluster, the average utilization of either node should leave room for the workload of the other node in case of failover. There should also be resources left for higher than average or peak times. For instance, if each node uses an average of 40% memory, then in case of failover, a single node will run at an average of 80% memory utilization. This leaves some room for higher than average usage without completely bogging down the remaining cluster node and forcing it to swap out too much memory.
Disk Performance

When looking at pages per second, a troublesome trend would show prolonged paging. Of course, here we see peaks because of large jobs running. One way to lessen the paging caused by such jobs would be to stagger their scheduling such that as few jobs are running as possible at any one time.

Current disk queue length can be a useful metric to see if your disks are a bottleneck. When disk IOPs are spread across many disks in a group, you can expect to see higher current disk queue lengths than if you were running on fewer disks. This is because all the disks in this group share the load of read and write requests. An average of two to three IOPs per disk is acceptable in most applications. If a group of disks share the load, then you can multiply the acceptable IOPs by the number of disks servicing a workload. As an example, if you have 100 disks in a (NetApp) aggregate, a reasonable number for current disk queue length would be somewhere around 200 to 300. In the graphs above, our workloads are being serviced by about 100 disks which means our current disk queue length is just fine.
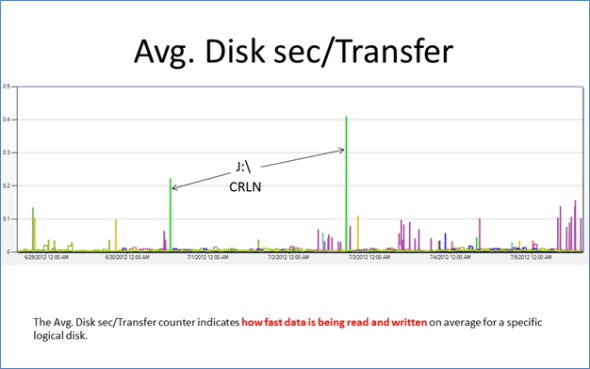
The average disk seconds per transfer metric tells us how fast data is being read and written. A more detailed view can be found by looking at average disk seconds per read and per write. Together with these and other metrics, such as disk queue length, we can get an overall picture of disk performance. If operations seem sluggish for a particular logical or physical drive, these views can confirm your suspicions. For instance, if we saw the J: drive, above, acting sluggishly, perhaps we would also see large queues and higher disk seconds per transfer, read or write. Higher transfer times could also indicate failed disks.
Network Performance

When looking at your network, the backlog or queue for packets to be sent, or Output Queue Length, will give you an indication of your network congestion at the NIC. With This particular SQL server had FCoE connections to storage but 1 GbE copper connections to the LAN. There were no significant queues seen at all on the front-side network which indicates a wide open pipe, if you will.





Great post!
Reblogged this on Jonathan Frappier Personal Blog and commented:
Great walk through of analyzing SQL server performance.
[…] I was recently asked to pull the performance metrics for a new SQL cluster at work. In an effort to finally get back to blogging, I thought I’d share my results and how someone else may be ab… […]
Nice work!
How can we get those cluster / node information and performance counters , via wmi classes (vbscript) or any other API ?