
NetApp FAS2240-2 with DS4246 Expansion Disk Shelf Design
Posted: November 17, 2013 Filed under: NetApp, Storage | Tags: 2240-2, aggregate design, design document, fas design, fas2240, fas2240 design, fas2240-2, netapp design, raid design, raid type, storage design, storage networking, storage networking design 22 CommentsI recently had the opportunity to design and implement NetApp’s entry-level storage solution for a client and I’d like to take this chance to share my approach to the design decisions. One reason for posting this is to help others that may be contemplating similar designs. I know there are a lot of talented and experienced engineers out there that may come across this and I encourage you to comment on this design. I look forward to learning from your experiences and at the same time I hope mine can help others. I should note that the hardware purchased was outside the scope of this design as the decision had already been made, hardware ordered and shipped. Also, common sense says that I’ve changed hostnames and IP addresses to protect the innocent.
The hardware specifications include
| Feature | FAS2240-2 |
| Controller Form Factor | Single enclosure HA; 2 controllers in a 2U chassis |
| Memory | 6 GB per controller |
| CPU | Dual Core Intel Xeon C3528 @1.73 GHz, HT enabled |
| Onboard I/O: 6 Gb SAS | 2 |
| Onboard I/O: 1 GbE | 4 |
| Mezzanine I/O: 10 GbE | 2 |
In addition, a half-populated (12 disks) DS4246 disk shelf was purchased with 7.2k rpm, 2TB SATA disks. The disks internal to the controller chassis are 24x10k rpm, 900GB SAS disks. Also of note is that there is no flash storage included in this design – no SSDs and no Flash Cache (FAS2240s don’t support Flash Cache anyways).
Implement & test virtual machines, VDIs or workstations on the cloud in real-time along with your favorite Windows apps on your phone with CloudDesktopOnline. Learn more about cloud/networking/IT solutions by visiting Apps4Rent.com.
Sponsored Ad
Requirements
The requirements included the general, “best performance, most capacity, and no single-points-of-failure.” Beyond this, the purpose of the storage was to provide extra capacity for ESXi hosts that had not been properly accounted for in the acquisition of a second company. Essentially, they ran out of storage and this system was to provide the extra capacity needed. Additionally, the storage system will not be joined to a domain for three reasons:
- CIFS will not be configured
- Local administrator accounts will be used
- Plans for restructuring Active Directory are in progress
Constraints
During the design workshop, the following constraints were identified:
- Storage networking included 2 Cisco 3560-X 48-port gigabit switches. These switches are non-stackable and therefore, do not support multi-chassis link aggregation.
- iSCSI is the protocol of choice by the client because they are currently using it in production and the FAS2240 was purchased without fibre channel target adapters.
- 1 Gbps storage networking will be used because the client does not have 10 Gbps switches and the 3560-X only supports 1 Gbps. The FAS2240s were purchased with the dual-port 10 Gbps mezzanine adapters, though, so future upgrades to 10 Gbps networking is possible at a later time.
- Jumbo frames will also be used because the ESXi hosts accessing the storage system are already configured to use jumbo frames
Assumptions
It was assumed early on, until a later site survey confirmed, that 6U of rack space was available as well as redundant power and open ports on the 3560-Xs.
Risks
Risks are identified as design alternatives and discussed in the relevant sections below.
Network Information
The following network information will be used to implement this design.
| Requirement | Controller1 | Controller2 |
| Hostname (standard 15 char.) | CONTROLLER-A | CONTROLLER-B |
| Mail Server | 10.10.10.5 | 10.10.10.5 |
| Autosupport From Address | it@company.com | it@company.com |
| Management VLAN ID | 50 | 50 |
| Management IP address (e0M) | 10.10.1.150 | 10.10.1.170 |
| Service Processor IP address (SP) | 10.10.1.160 | 10.10.1.180 |
| Management subnet mask | 255.255.255.0 | 255.255.255.0 |
| Management default gateway | 10.10.1.1 | 10.10.1.1 |
| iSCSI VLAN ID (iSCSI subnet 1) | 27 | 27 |
| iSCSI IP address 1 | 10.10.27.10 | 10.10.27.11 |
| iSCSI subnet mask | 255.255.255.0 | 255.255.255.0 |
| iSCSI VLAN ID (iSCSI subnet 2) | 28 | 28 |
| iSCSI IP address 2 | 10.10.28.10 | 10.10.28.11 |
| iSCSI subnet mask | 255.255.255.0 | 255.255.255.0 |
DNS and NTP
This implementation will not include Active Directory integration because of changes planned to the network. DNS will not be used from the controllers either. NTP will be configured, however. The table below details the NTP servers to be used for the project.
| NTP Server 1 | 198.50.152.100 |
| NTP Server 2 | 173.230.149.23 |
AutoSupport
AutoSupport is an integrated monitoring and reporting feature that checks the health of AutoSupport-enabled NetApp systems on a continual basis. It is an effective troubleshooting tool for both users and NetApp technical support. AutoSupport can help NetApp technical support notify users of failed components, unplanned HA failovers, and more. It is highly recommended to enable AutoSupport. The following AutoSupport options are enabled:
options autosupport.from it@company.com options autosupport.mailhost 10.10.10.5 options autosupport.noteto it@company.com options autosupport.to it@company.com</span>
Controller Overview
The controllers in this design will provide resources for Client virtual machines and block data access via iSCSI for physical hosts such as Microsoft SQL Servers.
The physical and virtual networking is configured through the use of a text file that holds configuration commands. The commands in the file are executed upon each reboot. The text file’s directory path is /etc/rc. This is the most important user configurable file in the system. Ensure this file is always correct. Other important information in this file includes the hostname definition, flow control settings, MTU sizes, interface group creation, VLAN creation, default and static routes, and name resolution configuration.
Another important file for each controller is the /etc/hosts file. This file resolves hostnames to IP addresses. Several storage system functions rely on hostname resolution. Therefore it is extremely important to ensure the file’s contents are correct.
Controller 1 and Controller 2 will be configured as a High-Availability (HA) Pair. If an entire controller should fail, the surviving controller will be configured to assume the identity of the failed controller. In the event of a controller failure, the surviving controller will continue serving data to the failed controller’s clients and hosts as well as its own. This HA functionality is obtained through two mechanisms. An interconnection exists between the controllers inside the chassis over which heartbeats (among other HA traffic streams) are shared. Mailbox disks are also configured automatically by Data ONTAP. These disks act as a second heartbeat mechanism as each controller will continually write bits of data to the mailbox disks. If a controller fails to send internal HA interconnect heartbeats and also fails to update its mailbox disks, then the surviving controller can safely assume the other controller has failed and will initiate a takeover of the failed controller’s disks.
Security Design
NetApp recommends configuring SSH and SSL immediately after initial setup of Data ONTAP. This best practice enables encryption for secure administration of each storage system. Additional recommendations include using only SSHv2. Although SSHv1 is supported in Data ONTAP, it has known exploitable vulnerabilities that can be prevented only by using SSHv2 exclusively.
The SSL protocol improves security by providing a digital certificate that authenticates storage systems and allows encrypted data to pass between the system and a browser. SSL is built into all major browsers. Therefore, installing a digital certificate on the storage system enables the SSL capabilities between the system and browser.
Data ONTAP supports SSLv2 and SSLv3. This design will use SSLv3 because it offers better security protections than those of previous SSL versions.
Setting up SSH
The following configuration will be used to setup SSH on each controller.
filer> secureadmin setup ssh SSH Setup --------- Determining if SSH Setup has already been done before...no SSH server supports both ssh1.x and ssh2.0 protocols. SSH server needs two RSA keys to support ssh1.x protocol. The host key is generated and saved to file /etc/sshd/ssh_host_key during setup. The server key is re-generated every hour when SSH server is running. SSH server needs a RSA host key and a DSA host key to support ssh2.0 protocol. The host keys are generated and saved to /etc/sshd/ssh_host_rsa_key and /etc/sshd/ssh_host_dsa_key files respectively during setup. SSH Setup will now ask you for the sizes of the host and server keys. For ssh1.0 protocol, key sizes must be between 384 and 2048 bits. For ssh2.0 protocol, key sizes must be between 768 and 2048 bits. The size of the host and server keys must differ by at least 128 bits. Please enter the size of host key for ssh1.x protocol [768] : 1920 Please enter the size of server key for ssh1.x protocol [512] : 2048 Please enter the size of host keys for ssh2.0 protocol [768] : 2048 You have specified these parameters: host key size = 1920 bits server key size = 2048 bits host key size for ssh2.0 protocol = 2048 bits Is this correct? [yes] Setup will now generate the host keys. It will take a minute. After Setup is finished the SSH server will start automatically. Fri Jul 23 13:36:39 GMT [secureadmin.ssh.setup.success:info]: SSH setup is done and ssh2 should be enabled. Host keys are stored in /etc/sshd/ssh_host_key, /etc/sshd/ssh_host_rsa_key, and /etc/sshd/ssh_host_dsa_key.
Set the following options that control SSH connections after setup.
options ssh.enable on options ssh.access all options ssh.idle.timeout 15 options autologout.telnet.timeout 15
Setting up SSL
The following SSL parameters will be configured for each NetApp system:
filer> secureadmin setup ssl Country Name (2 letter code) [US]: US State or Province Name (full name) [California]: Missouri Locality Name (city, town, etc.) [Santa Clara]: Waynesville Organization Name (company) [Your Company]: BigCountryToys Organization Unit Name (division): IT Common Name (fully qualified domain name) [CONTROLLER-A]: Administrator email: it@company.com Days until expires [5475] : Key length (bits) [512] : 2048 Fri Jul 23 14:12:05 GMT [secureadmin.ssl.setup.success:info]: Starting SSL with new certificate.
Set the following options that control SSL connections after setup.
options ssl.enable on options ssl.v2.enable off options ssl.v3.enable on
General Security Options
Remote Connection Options
The following general security options will be configured which will also allow for standard management tool connectivity.
options httpd.admin.enable on options httpd.admin.ssl.enable on options rsh.access none options telnet.access none options webdav.enable off
Additional Users and Password Requirements
For increased security, it is recommended to add users to the local Administrators group and then disable the root user. Password complexity requirements are also configured to adhere to company policy. In order to accomplish this, the following commands will be used on each controller:
useradmin user add <username> -g Administrators -m <min-age> -M <max-age> useradmin domainuser add <username> -g Administrators –m <min-age> -M <max-age> options security.passwd.rootaccess.enable off options security.passwd.rules.everyone on options security.passwd.rules.minimum 8 options security.passwd.rules.maximum 14 options security.passwd.rules.minimum.alphabetic 1 options security.passwd.rules.minimum.digit 1 options security.passwd.rules.minimum.symbol 1 options security.passwd.rules.history 6 options security.passwd.lockout.numtries 6 options security.passwd.firstlogin.enable on
diaguser
The diagnostic user should be locked when not in use and the password should be changed after each time it is used. The following commands will be used to lock this user:
priv set advanced useradmin diaguser lock useradmin diaguser show useradmin diaguser password
Service Processor Security
The Service Processor (SP) will also be configured to provide more security by forcing users to connect via SSH. Idle connection timeout will also be used. The following commands will be used to force SSH connections with an idle timeout:
options sp.ssh.access all options sp.autologout.enable #default is on options sp.autologout.timeout 10
Message of the Day Logon Banner
The message of the day (MOTD) logon banner will be presented as each login. This banner will be configured as shown below.
filer> wrfile /etc/motd **************System Use Notice****************** Unauthorized access to this system is prohibited! *************************************************
Hit Ctrl-C to finish writing to the file
Active Directory Authentication
Active Directory authentication can be used to enable directory services to authenticate storage administrators instead of using local user accounts. The following command can be used to enable this (after CIFS has been configured for use in a domain):
useradmin domainuser add domain\<groupname> –g Administrators
Protocol Access Filters
Protocols will be blocked from using certain interfaces based on this design.
options interface.blocked.cifs e0M options interface.blocked.nfs e0M options interface.blocked.iscsi e0M options interface.blocked.ftpd e0M options interface.blocked.snapmirror e0M options interface.blocked.mgmt_data_traffic on
There are protocol access filters for the following protocols: RSH, telnet, SSH, HTTP, SNMP, NDMP, SnapMirror, and SnapVault. The following commands can be used to enable these protocols:
options ssh.access all options snapmirror.access options snapvault.access
The following protocols are supported by vFiler units: CIFS, NFS, RSH, SSH, iSCSI, FTP, and HTTP. These protocols can be filtered on future vFilers added to the system with the following commands:
vfiler allow vfiler1 proto=nfs proto=ssh proto=cifs proto=iscsi proto=http... vfiler disallow vfiler1 proto=rsh proto=ftp...
Storage Design
RAID Type
RAID-DP, or double parity, is the default RAID type used in NetApp storage systems today and is the chosen RAID type for this design. RAID4 is also available. RAID-DP is the best choice today for NetApp systems because it provides the best protection for data and, along with NetApp’s Write Anywhere File Layout (WAFL), provides the best available throughput when writing data to disk. Together, RAID-DP and WAFL provide enterprise-class performance and protection. RAID-DP is based on RAID6 and uses two disks for parity which allows for a failure of any two disks in a particular RAID Group before data loss will occur. The data or parity lost in the failed disks can be recomputed by the remaining disks. Should a disk failure occur, disks configured as hot spares are automatically added to the affected aggregate and rebuild operations are commenced to recover lost data or parity information. If a read request is initiated while the rebuild is taking place, the lost bits requested (or parity) are recalculated based on existing data and parity. While the disks are being rebuilt, the aggregate is operating in a degraded state but access to the storage system is not lost.
Aggregate Type
Today’s NetApp storage systems, and the configuration chosen for this design, by default use 64-bit aggregates. Earlier 32-bit aggregates were limited in size to 16TB. With disk sizes today approaching 4TB, it would take very few disks to fill an aggregate leaving the number of spindles supplying IOPS too few to meet modern storage requirements. 64-bit aggregates on the FAS2240 can grow up to 120TB.
Under normal circumstances, capacity SATA drives and performance SAS drives should not be mixed in the same aggregate. Due to the slower rotation of SATA drives, mixing drives in aggregates will cause writes to the SAS drives to slow down and reduce performance. Given this and the size of the deployment, two aggregates will be created: one for SAS disks and one for SATA disks. The following naming scheme is suggested, but can be modified based on Client requirements.
| Aggregate Name | Disk Type |
| aggr_sas1 | SAS |
| aggr_sata1 | SATA |
RAID Group Sizing
The initial RAID Group size will be configured as 23 disks for SAS and 12 disks SATA aggregates. A RAID Group size of 23 for SAS disks will maximize performance by maximizing the number of spindles backing the aggregate, reduce lost capacity due to parity drives, as well as ease the addition of disk shelves into the aggregate in the future.
The FAS2240-2 storage system has 24x900GB SAS disks in the same chassis as the controllers. One SAS disk will be reserved as a hot-spare and therefore is not included in any aggregates. The hardware was purchased with a four-hour hardware replacement response time so one hot-spare should be sufficient (if the Client would like more security with regard to disk failures, two disks may be set aside as hot-spares with the tradeoff being less usable storage but more security). This leaves 23 disks for data and parity. A RAID Group size of 23 disks and a single SAS aggregate will result in one RAID Group being created. RAID Group 1 (RG1) will be full and use all 23 drives.
The second shelf is a half-populated DS4246 with 12x2TB SATA disks. The SATA disks will be configured in a single aggregate with a RAID Group size of 12. Note: The maximum RAID Group size for SATA disks is 20. There will be one disk reserved as a hot spare. The only configured RAID Group, RG1, will not be a full RAID Group because one disk must be configured as a hot spare. This leaves 11 disks for data and parity. A summary of the RAID Group configurations is shown in the table below.
| Controller | RAID Group | Data Disks | Parity Disks | Total Disks |
| Controller1 | RG1 | 21 | 2 | 23 |
| Controller2 | RG1 | 9 | 2 | 11 |
Should expansion shelves be added in the future, disks should be added to the SAS aggregate keeping in mind a RAID Group size of 23. When additional disks are added to existing aggregates, any drive deficient RAID Groups will have disks added until the RAID Group is full and further disks will be used to create additional RAID Groups. An additional 24-disk shelf should be configured with at least one hot spare, leaving 23 disks available to add to the existing SAS aggregate. Adding all 23 disks will result in two total RAID Groups comprised of 46 disks. The drive layout per RAID Group would look like the following table.
| RAID Group | Data Disks | Parity Disks | Total Disks |
| RG1 | 21 | 2 | 23 |
| RG2 | 21 | 2 | 23 |
This configuration adheres to NetApp’s recommendation of leaving no RAID Group deficient by more than one less than the number of RAID Groups in the aggregate.
The following commands will create the two named aggregates with the chosen RAID Group size using a number of disks of the identified disk type.
- aggr create aggr_sas1 -r 23 -T SAS 23
- aggr create aggr_sata1 -r 12 -T SATA 11
Performance Estimates
IOPS numbers by themselves should only be used as a guide when determining the expected performance of a storage system. Raw IOPS per disk drive are a factor of the average seek time and average rotational latency. Block sizes that applications use to read and write to storage as well as end-to-end latency in the storage network are also factors that affect performance. With this understanding, the following table shows the raw IOPS available for each aggregate based on the number of disks assigned to that aggregate. Actual performance will vary with workloads.
| Aggregate | Assigned Drives | Estimated IOPS per Drive | Estimated IOPS |
| aggr_sas1 | 23 | 140 | 3,220 |
| aggr_sata1 | 11 | 75 | 825 |
Root Volumes
In order to maximize the number of data drives available, the Data ONTAP root volumes will reside on the data aggregates. They will not have dedicated aggregates created for them. The benefit of this is that two disks are not lost to parity for each controller. In addition, the three disks worth of IOPS that would have been dedicated to each root aggregate are now included in a data aggregate. This means there is more usable disk space and performance for workloads. It is important to note that user data should never be stored on the root volume, vol0. Storing user data on the root volume risks the root volume becoming full and the Data ONTAP operating system going offline and crashing the controller.
Right-sizing and Usable Capacity
Since each drive manufacturer ships like-capacity drives with different numbers of sectors, it is important that the file system format normalizes the actual size of like-capacity drives. The process of normalization is known as right-sizing. Once the right-sizing process is complete, the resulting usable capacity can be referred to as the right-sized capacity of the drive. The sysconfig –r command will always display the right-sized usable capacity of a drive. The capacities listed in the below table represent this usable capacity minus the additional factors that affect usable capacity when aggregates are created, such as
- 10% WAFL file system reserve
- 5% aggregate Snapshot reserve
This does not include the default 5% Snap Reserve configured on all NAS Flexible Volumes by default. SAN FlexVols are created with a default Snap Reserve of 0%. All capacities shown below are in GB.
| Controller | Allocated Data Disks | Raw Disk Capacity | Right-Sized Disk Capacity | Usable Capacity |
| Controller1 | 23 | 900 | 836 | 16,343 |
| Controller2 | 11 | 2000 | 1,655 | 15,474 |
The usable capacities shown above also do not take into consideration capacity lost to RAID-DP parity information. When parity is included, the usable capacity looks like the table below. Again, all capacities are shown in GB.
| Controller | Usable Capacity before Parity | Usable Capacity after Parity |
| Controller1 | 16,343 | 14,671 |
| Controller2 | 15,474 | 12,164 |
Spare Drive Assignment
Disks owned by a controller but not assigned to an aggregate are known as spare disks. How the spare disks are allocated is described below.
There is one hot spare per drive type per controller. These spare disks are reserved for disk failures. Controller 1 has one hot spare SAS disk and Controller 2 owns one hot spare SATA disk. This decision was made because of the type of support agreement Client has for its disks. There is a four hour window for drive replacement. Because AutoSupport will be configured, when a drive fails, another one can be ordered quickly. Storage Administrators must ensure that failed drives are replaced immediately. RAID-DP offers protection for up to two disk failures within a RAID Group. When a disk fails and a hot spare is used to replace it, that RAID group cannot perform optimally while the failed drive is rebuilt on the hot spare. It will run in a degraded state until the rebuild is complete. If failed disks are not replaced immediately, continued drive failures will force the RAID Group to run in a degraded state for extended periods of time. If three disks fail in a RAID Group without being replaced, or while disks are being rebuilt, data loss will occur. This is why Storage Administrators must be aware of failed drives and replace them as soon as possible.
Disks can be assigned but not removed from aggregates. If all spare drives are assigned to aggregates and no hot spares are left, aggregates will operate in a degraded state until failed drives are replaced. This is not optimal and could lead to data loss. There is no way to differentiate between hot spares and reserved spare drives. To maximize data security, there must always be at least one hot spare per drive type per controller.
Storage Networking Design
The storage networking in this design will be configured with the requirement to connect ESXi servers for iSCSI connectivity. Further storage protocols, such as CIFS or fibre channel, can still be implemented at a later time. Any storage networking solution will depend on the switches used and their capabilities. The best designs for performance and availability use one of the following three switching platforms or others that support some type of Multi-chassis Link Aggregation (MLAG).
- Cisco Nexus and Virtual Port Channels (vPC)
- Cisco Catalyst 6500 with Virtual Switching System (VSS)
- Cisco Catalyst 3750 with cross-stack Etherchannel
A constraint of this design is that the Ethernet switches used for storage traffic are Cisco Catalyst 3560-Xs and they do not support MLAG features. Because of this, a link failover design is used for the NetApp controllers. This design requires two links to each storage network switch with only one link to each switch active at any one time. A controller is assigned two IP addresses each in two different subnets meaning the ESXi hosts must have two VMKernel ports, one in each subnet. This design does not use Etherchannels at all, relying instead on the ESXi hosts to detect link failures, VMKernel port binding, and iSCSI multi-pathing and the storage controllers to use single-mode interface groups and the ifgrp favor command with active-standby NICs. Each ESXi host should be configured with the Round Robin Path Selection Plugin (PSP) to actively send I/O down multiple paths. The network diagram below shows this configuration. Subnet 1 is shown in red and Subnet 2 is shown in blue. The inter-switch links need to trunk both Subnets to account for a particular failure scenario discussed below. The dashed lines represent inactive links. The controller will place these inactive links in stand-by mode and they will not be available to pass traffic under normal conditions.

Normal Traffic Patterns
Normal traffic patterns are shown in the figure below. Each ESXi host’s iSCSI traffic would follow the paths shown. For example, host ESXi1 will send packets out vmnic1 on Subnet 1 and through Switch A. The e0a port on the controller is the only port through which Subnet 1 iSCSI traffic can arrive on.
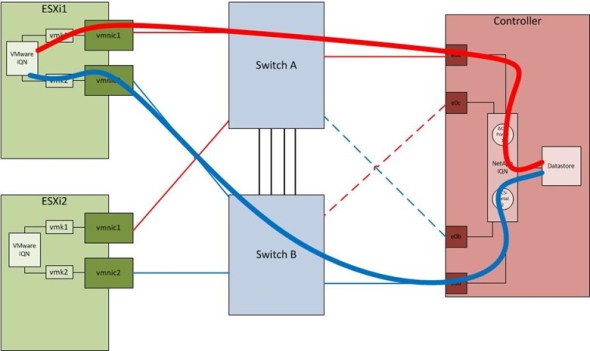
Traffic Patterns after Failures
There are three network failure scenarios that are discussed below to show how this design is fault-tolerant as well as to illustrate what kind of traffic flows to expect under failure conditions.
Host-side Failure Scenario
The first failure scenario is that of a host-side failure and is shown in the figure below. This could be a failed NIC in a server, a pulled or failed cable between the server and the switch, or a failed switch port. When a host-side failure occurs, the ESXi host will sense that the path has failed and that it can no longer send traffic over that particular link and that particular subnet, Subnet 1. It will then proceed to send traffic through the surviving link on Subnet 2. Effectively half of the bandwidth to the failed ESXi host has been lost. The NetApp controller, however, does not know that a host-side failure has occurred. No changes are made to the controller interfaces and no controller interfaces are failed over. The iSCSI session from vmk1 to iSCSI Portal 1 on the NetApp controller will simply time out.

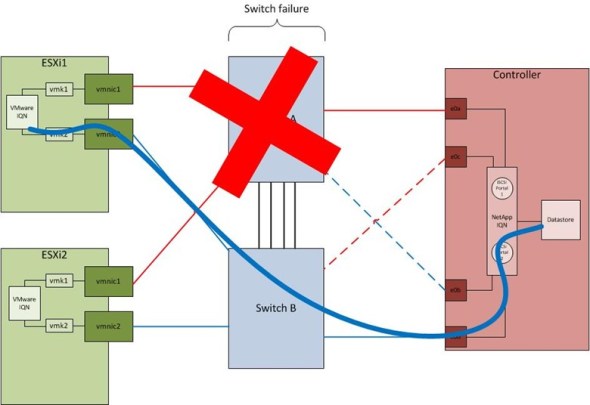
Switch Failure Scenario
The second failure scenario is a switch failure. In the example below, Switch A fails. When this happens, both the ESXi host and NetApp controller will react. The ESXi host will act similarly to the above host-side failure situation and simply use the remaining VMKernel port to send iSCSI traffic on Subnet 2. This cuts the available bandwidth to the host in half. Even though the NetApp controller will failover from port e0a to port e0c, no Subnet 1 traffic (red subnet) is being received on Switch B in order to forward to port e0c on the controller. Switch A is completely dead and all ESXi hosts terminate their Subnet 1 links on Switch A, therefore, no Subnet 1 traffic reaches the controller. As is the case for the host-side failure, the iSCSI session from vmk1 to iSCSI Portal 1 on the NetApp controller will simply time out.
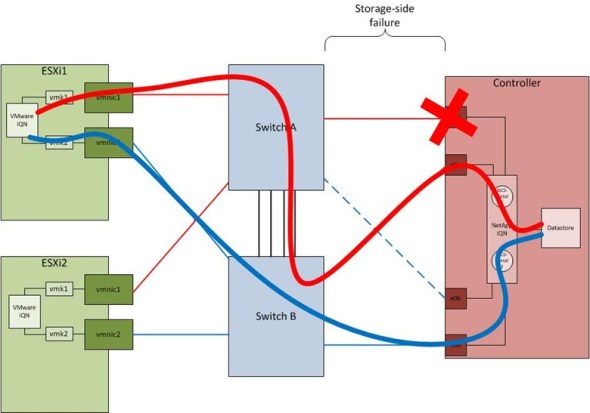
Storage-side Failure Scenario
The last and final storage network failure scenario is that of a storage-side failure. This could be a failed Ethernet port on the controller, a failed cable, or a failed switch port. This is the only case in which bandwidth is not reduced but instead, redirected. Once the failure occurs, the controller will failover from the active interface to the stand-by interface of the single-mode interface group. In the figure below, the failover is from e0a to e0c. Traffic will traverse the inter-switch link, on which both iSCSI VLANs are trunked, and end up at the new target end-point for Subnet 1. This configuration is clearly suboptimal because one iSCSI path has an extra hop. The failed hardware should be replaced as soon as possible.
Configuration Files
The following switch configurations are representative of those used for management and data ports.
Management Ports
interface GigabitEthernet0/x description << NetApp Controller A e0M >> switchport mode access switchport access vlan 50 spanning-tree portfast spanning-tree bpduguard enable spanning-tree guard root
Data Ports
interface GigabitEthernet0/x description << NetApp Controller A e0a >> switchport trunk encapsulation dot1q switchport mode trunk spanning-tree portfast trunk spanning-tree bpduguard filter
The following files are used to configure the NetApp controllers.
Controller 1 /etc/rc
hostname controller-a ifgrp create single VIF01 e0a e0c ifgrp favor e0a ifgrp create single VIF02 e0b e0d ifgrp favor e0d vlan create VIF01 27 vlan create VIF02 28 ifconfig e0a flowcontrol none mediatype auto mtusize 9000 ifconfig e0b flowcontrol none mediatype auto mtusize 9000 ifconfig e0c flowcontrol none mediatype auto mtusize 9000 ifconfig e0d flowcontrol none mediatype auto mtusize 9000 ifconfig e0M `hostname`-e0M netmask 255.255.255.0 ifconfig VIF01-27 `hostname`-VIF01-27 netmask 255.255.255.0 mtusize 9000 partner VIF01-27 ifconfig VIF02-28 `hostname`-VIF02-28 netmask 255.255.255.0 mtusize 9000 partner VIF02-28 route add default 10.10.1.1 1 options dns.enable off options nis.enable off routed on savecore
Controller 1 /etc/hosts
10.10.1.150 controller-a controller-a-e0M 10.10.1.170 controller-b controller-b-e0M 10.10.27.10 controller-a-VIF01-27 10.10.28.10 controller-a-VIF02-28 10.10.27.11 controller-b-VIF01-27 10.10.28.11 controller-b-VIF02-28
Controller 2 /etc/rc
hostname controller-b ifgrp create single VIF01 e0a e0c ifgrp favor e0a ifgrp create single VIF02 e0b e0d ifgrp favor e0d vlan create VIF01 27 vlan create VIF02 28 ifconfig e0a flowcontrol none mediatype auto mtusize 9000 ifconfig e0b flowcontrol none mediatype auto mtusize 9000 ifconfig e0c flowcontrol none mediatype auto mtusize 9000 ifconfig e0d flowcontrol none mediatype auto mtusize 9000 ifconfig e0M `hostname`-e0M netmask 255.255.255.0 ifconfig VIF01-27 `hostname`-VIF01-27 netmask 255.255.255.0 mtusize 9000 partner VIF01-27 ifconfig VIF02-28 `hostname`-VIF02-28 netmask 255.255.255.0 mtusize 9000 partner VIF02-28 route add default 10.100.1.1 1 options dns.enable off options nis.enable off routed on savecore
Controller 2 /etc/hosts
10.10.1.15 controller-a controller-a-e0M 10.10.1.17 controller-b controller-b-e0M 10.10.27.10 controller-a-VIF01-27 10.10.28.10 controller-a-VIF02-28 10.10.27.11 controller-b-VIF01-27 10.10.28.11 controller-b-VIF02-28
Port Maps and Rack Elevations
SAS Cabling
The SAS cabling table and figure below shows how the expansion shelf is cabled. The table below should be referenced when additional shelves are added.
| Path | From SAS Port | To SAS Port |
| Path 1 | Controller 1, 0a | DS4246, IOM A, square port |
| DS4246, IOM A, circle port | Controller 2, 0b | |
| Path 2 | Controller 2, 0a | DS4246, IOM B, square port |
| DS4246, IOM B, circle port | Controller 1, 0b |
Controller 1 is on the left and Controller 2 is on the right. The solid lines denote primary data paths. Dashed lines represent secondary HA paths.

ACP Cabling
NetApp recommends using the ACP protocol because it enables Data ONTAP to manage and control the SAS disk shelf storage subsystem. It uses a separate network from the data path, so management communication is not dependent on the data path being intact and available. Use of ACP requires that all disk shelf I/O Modules (IOMs) and storage controllers connect through the ACP ports on the IOMs and the designated network interface on each controller which appears as the locked wrench port on each controller.
| From ACP Port | To ACP Port |
| Controller 1 (locked wrench port) | DS4246, IOM A (square) |
| DS4246, IOM A (circle) | Controller 2 (locked wrench port) |

Ethernet Cabling
| Source Port | Function | Speed | Dest. Switch | Dest. Port |
| Controller 1 e0M | Management | 100 Mbps | SW1 | 33 |
| Controller 1 e0a | Active iSCSI (VLAN 27) | 1 Gbps | SW1 | 21 |
| Controller 1 e0b | Active iSCSI (VLAN 28) | 1 Gbps | SW2 | 22 |
| Controller 1 e0c | Stand-by iSCSI (VLAN 27) | 1 Gbps | SW1 | 23 |
| Controller 1 e0d | Stand-by iSCSI (VLAN 28) | 1 Gbps | SW2 | 24 |
| Controller 2 e0M | Management | 100 Mbps | SW2 | 28 |
| Controller 2 e0a | Active iSCSI (VLAN 27) | 1 Gbps | SW1 | 22 |
| Controller 2 e0b | Active iSCSI (VLAN 28) | 1 Gbps | SW2 | 43 |
| Controller 2 e0c | Stand-by iSCSI (VLAN 27) | 1 Gbps | SW1 | 24 |
| Controller 2 e0d | Stand-by iSCSI (VLAN 28) | 1 Gbps | SW2 | 45 |
Serial Cabling
There are no serial concentrators in the environment so the serial ports on the controllers will not be cabled.
Power Cabling
The following table shows which ports each power supply plugs into.
| Device | Power Supply | Power Circuit | PDU Port |
| FAS2240-2 | A | A | B1-8 |
| B | B | B1-8 | |
| DS4246 | A | B | B1-5 |
| B | A | B1-1 |
Rack Elevations
Both devices were racked in Row 1, Rack 5. The FAS2240-2 controller and disk chassis is racked at 15-16U and the DS4246 disk shelf is racked at 11-14U.





Excellent guide!
Very nice. Could you add how did you sized volumes / qtress
Hi Greg,
This particular deployment didn’t involve sizing their storage units – rather I just showed them how to create volumes and LUNs. The answer to your question would make a good post in itself.
Thanks,
Mike
Hey Mike, thanks for the great howto. If you were to purchase two new 10GbE-capable switches for this deployment, what would you use? Brocade, Cisco, Juniper?
Also, would you recommend iSCSI or NFS for the VMware volumes? I’ve seen mixed feedback so far and it would be great to see your views on this?
Many thanks once again for the great post!
Hi George,
I’m biased because I’m a Cisco guy. I can’t speak either way about Brocade or Juniper. Two things come to mind though when deciding which vendor to go with. One is whether they support some type of multi-chassis link aggregation, which I bet “the other two” do support, and does your company have the skills necessary to manage the chosen vendor. If you have a bunch of Cisco guys managing your network, you’ll likely want to lean Cisco, right? In most deployments, you’d be looking at a 5500-series Nexus switch or similar. Then you’d get into a bunch of, it depends questions that you’d want to discuss with your team and a competent Cisco consultant.
I have a slightly similar answer for the iSCSI / NFS debate. The big “it depends” answer comes from what you’re using today and what you’re comfortable with. Either one can work well and it’s not necessarily about performance. This question is asked so much I’ve created some notes in Evernote for easy reference. These are the pros and cons that I can agree with. Some things I can’t agree with relate to how “easy” either protocol is to implement because it’s too subjective.
iSCSI Pros
* 10G Ethernet is well understood
* Can multipath
iSCSI Cons
* Per LUN I/O queue
* Datastore size limit determined by vSphere
NFS Pros
* 10G Ethernet well understood
* Datastore size limit is determined by the array, generally much larger than vSphere LUNs
* Per file (not per LUN) I/O queue
* File-level locking, not datastore level-locking
* No VMFS upgrades
NFS Cons
* Application support (MSCS, etc.)
Personally, I’d lean NFS and use iSCSI for edge cases.
All the best,
Mike
Thank you very much for the reply! understood for both.
I will also try a lab experiment, to configure 4 ucs rack servers running esxi (2 clusters with 2 hosts per cluster), and only use 2 whitebox 10GbE switches for connectivity, running Cumulus linux. I thought about this when reading the solution design for VMware NSX network virtualization. most of the processing will take place inside the NSX virtual machines, so it should be possible. I will then try to interconnect with our FAS2240-2 for IP storage. I will post back once I have results!
Mismatch in ACP cabling section Graphics and the text is different (in second line) DS4246, IOM A (circle) Controller 2 (locked wrench port) actually it should be IOM B circle port to controller to Wrench port right ?
Yes, you’re right. I mistakenly left out the IOM A (circle port) to IOM B (square port) and incorrectly labeled the last connection. It should be IOM B (circle port) to Controller 2 (locked wrench port), as you noted.
Thanks!
Mike
Hi Mike,
when computing space/disks usage, you’re not taking account of disks you need to provide to the root aggregates of each controller.
All the best.
Hello,
There’s a Root Volumes section included that states the root volumes will reside on data aggregates to maximize usable capacity. It was a design decision made by the client when presented with the options. I used to be a fan of this configuration, but now I’m a little more conservative. I do a lot of small deployments and this type of capacity loss definitely hurts, but not as much as losing all your data when you need to revert an aggregate to a Snapshot just to recover your root vol.
All the best!
Mike
I understand the need to reduce the capacity penalty, but such kind of configuration could be a real pain in the arse if something goes wrong.
Hi
Just to say an excellent blog and interesting read, there were a few things there even I wasn’t aware of.
My question is do you know if ACP is only used on SAS disk trays?
I just brought a SATA disk tray based on a DS4246 and want to know if this should also be added to with regards to ACP? from the reading I have done It makes me think that ACP is only for SAS and not SATA.
Do you have an answer to this?
Many Thanks
Hi Ranj,
ACP is available for both SAS and SATA shelves. Check out the SAS and ACP cabling guide from my Box notes here https://app.box.com/s/qbkvcst84d2mk4besy2uhbiskk18lhlp
All the best,
Mike
Edit: As mentioned Emanuele, the DS4243 and DS4246 are, indeed, SAS shelves, but included SATA (or nearline/NL-SAS which are actually SATA disks with a SAS adapter) disks. SAS is the protocol and type of cabling between shelves and disks (which supports ACP), as opposed to fibre channel or SATA on DS14 shelves (which do not support ACP).
ACP works only with SAS, but ds42xx is a SAS shelf, and its disks are SAS or so called Near-Online SAS disks, hence I don’t see problems with ACP. However, ACP wasn’t supported on the older DS14 shelves, which were Sata boxes.
Thanks to you both for this feedback.
Sorry I have one more question on this.
I configured the ACP but when I run storage show acp, the ACP connecitvity status is showing ‘additional connectivity’ rather than ‘full connectivity’.
it now lists the disk tray but it’s marked as “inactive (no in-band connectivity).
is that what I would expect to see because the disks are SATA?
Thanks
Hello Ranj, it seems you have a shelf reachable on the ACP network but not by the data path, I suggest you double check connectivity.
About the capacity penalty due to root volume: I had a conversation with NetApp guys yesterday, and now, with cluster mode, I understood it’s possible to partition the disks used by root volume and don’t waste the remaining space.
Indeed. This is called Advanced Drive Partitioning and is available in clustered ONTAP 8.3 or later. This is a great leap forward for those SMBs that use entry-level arrays.
[…] included these options in a NetApp design I shared last […]
Hello I did this setup yeserday and it works fine 🙂 But now I must do the same, but with 2 DS4243, do you have a diagram about cabling for this ? Thanks
Hi there,
Here’s a quick sketch of what the cabling will look like.
https://app.box.com/s/0lkvc7iyop3loh6zy269e8ahnq4itwr6
All the best,
Mike
Hi can we option to use two AD server in single Storage..