SRM error – failed to recover datastore. An error occurred during host configuration
Posted: October 30, 2013 Filed under: SRM, VMware | Tags: An error occurred during host configuration, failed to recover datastore, site recovery manager, srm Leave a commentI’d like to share an error I was receiving when running test recoveries with SRM 5.1.1 on a NetApp, ONTAP version 8.1.2. The datastores in question were NFS. The error received in the SRM report is consistently in Section 4. Create Writable Storage Snapshot, but strangely, on differing datastores, first datastore 6, then on datastore 5, then back to datastore 6. This is without making changes to the environment in between tests. Weird, huh? The exact error in the report is

“Error – Failed to recover datastore ‘<datastore6>. An error occurred during host configuration.”
Coming soon: book review of VMware Workstation – No Experience Necessary
Posted: October 29, 2013 Filed under: Book Reviews Leave a comment Thanks again to Packt Publishing for the opportunity to review another of their many good titles around VMware technology. In appreciation for the reviews, they kindly keep my Kindle loaded with their tech tomes. The next review will be out in a few days over VMware Workstation – No Experience Necessary by Sander van Vugt (@sandervanvugt).
Thanks again to Packt Publishing for the opportunity to review another of their many good titles around VMware technology. In appreciation for the reviews, they kindly keep my Kindle loaded with their tech tomes. The next review will be out in a few days over VMware Workstation – No Experience Necessary by Sander van Vugt (@sandervanvugt).
I’ve used Workstation for years alongside my home test lab, but for me, the product shines most when I’m on the road and don’t have access to a full blown hardware lab. For technologists new to virtualization and veterans alike, Workstation is a useful tool to have. I look forward to reviewing Sander’s latest addition.
Integrating Cisco MDS 9124 switches with Nexus 5500s
Posted: October 28, 2013 Filed under: Cisco Nexus, Networking | Tags: 5500, 5548, 5596, 55xx, 9124, Cisco, cisco mds, fc, fibre channel, mds, Nexus Leave a commentI wanted to take a short minute and document the addition of a few Cisco MDS 9124s to our test lab at work. The purpose of the addition in the test lab is just to show the functioning and capabilities of the devices to work together. See my previous post on configuring native FC over a Nexus 5548 and 5596. The FC-specific portions of the MDS config are very similar to the Nexus line. Here’s what the middle state looks like. I haven’t taken the time to move the NetApp FC links to the MDS switches yet (or the UCS FC links instead), but the port provisioning process will be similar to those already documented in this post and the Nexus post. The Visio of what’s configured is below followed by my MDS configuration notes.

Book Review: vSphere High Performance Cookbook
Posted: October 27, 2013 Filed under: Book Reviews | Tags: book, book review, high performance, packet publishing, packt, packt publishing, performance, review, vmware, vmware performance, vsphere, vsphere performance Leave a comment I was graciously given the opportunity to read and review vSphere High Performance Cookbook, written by Prasenjit Sarkar (@stretchcloud) and published by Packt Publishing, whose subtitle states it has Over 60 recipes to help you improve vSphere performance and solve problems before they arise. Gulping down its chapters was easy after seeing that Prasenjit’s recipes included fixes for such common, and some not so common, misconfigurations or lack thereof.
I was graciously given the opportunity to read and review vSphere High Performance Cookbook, written by Prasenjit Sarkar (@stretchcloud) and published by Packt Publishing, whose subtitle states it has Over 60 recipes to help you improve vSphere performance and solve problems before they arise. Gulping down its chapters was easy after seeing that Prasenjit’s recipes included fixes for such common, and some not so common, misconfigurations or lack thereof.
SnapManager for SQL Sizing Case Study
Posted: July 10, 2013 Filed under: NetApp, SQL Server | Tags: netapp smsql, netapp smsql sizing, smsql, smsql sizing, snapmanager, snapmanager for sql, sql sizing 2 CommentsThis SnapManager for SQL case study was conducted for a real world client. Anything in this study that could identify the client has been removed from the article to protect their business. I wanted to take this opportunity to document the procedures and explanations for sizing such an environment.
This particular implementation involved a three node SQL Server 2012 AlwaysOn Availability Group running on Server 2008R2 physical servers. The databases are new and haven’t been populated with data, yet, so the sizing had to take these “known unknowns” into account. SnapManager for SQL 6.0 and SnapDrive for Windows 6.5 were used. The NetApp system includes a FAS3220 in an HA pair running Data ONTAP 8.1.2 7-mode.
Typical best practices were used such as using volume autogrow, letting SnapManager take care of Snapshot deletions, etc. I don’t address thin provisioning, deduplication, or space reservations in this document beyond saying that Fractional Reserve is kept at its default 0% and SnapReserve is changed to 0%. I suggested the LUNs and volumes be thinly provisioned because the client has a trained and dedicated NetApp Administrator on staff with the tools and alerts necessary to manage aggregate capacity properly. The storage deployment is a new, mid-size deployment and capacity is already at a premium. Thin provisioning now, monitoring, and growing or shrinking volumes and LUNs as actual growth is observed was advised so as not to waste space. Deduplication was used on the database volumes and CIFS shares – not the transaction logs, SnapInfo, TempDB, or System Databases.
A logical diagram of a SQL Server replication scheme is show below. There is an OLTP database that is relatively large compared to the many smaller databases that comprise the Data Warehouse (DW). Each Primary Replica will be at Site A hosted, under normal conditions, on separate nodes. These nodes will then synchronously replicate within the same site to the other node. Asynchronous replication will happen across sites to Site B and a third node.

NetApp built-in packet capture
Posted: June 24, 2013 Filed under: NetApp, Storage | Tags: capture, netapp packet capture, packet, packet capture, pktt, pktt dump, pktt start, pktt stop 2 Comments I first had to do this at the direction of NetApp tech support. Ever since, I found myself searching my email for it so I could use it again and again. I finally took the hint and decided to post it here for my reference – but maybe you could use it as well. Oh, and copy it to Evernote, too.
I first had to do this at the direction of NetApp tech support. Ever since, I found myself searching my email for it so I could use it again and again. I finally took the hint and decided to post it here for my reference – but maybe you could use it as well. Oh, and copy it to Evernote, too.
They way I use this, as you might expect, is to start the capture, perform the operation that’s failing, and then stop the capture. So as not to capture too much traffic and therefore have to wade through all of it, I try to perform those steps rather quickly. But then again, if you know a few useful features of Wireshark, you can get around in the capture file pretty easily. So here you are.
filer> pktt start all -d /etc/crash
<perform the operation that fails here>
filer> pktt dump all filer> pktt stop all
Add a VLAN to a UCS blade via the CLI
Posted: June 21, 2013 Filed under: Cisco UCS | Tags: add vlan ucs cli, ucs cli, vNIC 2 Comments So my UCS Manager GUI was having certificate problems today in my test lab and I really wanted to get something done. I think I need to update UCSM from 2.0(1s) to one of the latest, but that’s a project in itself, especially if I can’t just click-click-click my way through. What I really wanted to do was add a couple existing VLANs to the vNIC of an ESXi host on a blade (so I could vMotion some stuff around). Of course, with the GUI, it’s a few clicks. Without the GUI (and not knowing where to go in the CLI), I was at a bit of a loss.
So my UCS Manager GUI was having certificate problems today in my test lab and I really wanted to get something done. I think I need to update UCSM from 2.0(1s) to one of the latest, but that’s a project in itself, especially if I can’t just click-click-click my way through. What I really wanted to do was add a couple existing VLANs to the vNIC of an ESXi host on a blade (so I could vMotion some stuff around). Of course, with the GUI, it’s a few clicks. Without the GUI (and not knowing where to go in the CLI), I was at a bit of a loss.
The UCS CLI guide wasn’t helpful as it was more for managing the hardware or upstream configs – not so much for what would seem like a task made for UCSM. So to get on with it, let me share the quick config for adding VLANs to vNICs. This post actually got me in the ballpark (just search for “vlan” in the post), but from there, I was on my own!
New to NetApp? Here are the default Snapshot settings explained for ONTAP 8.1
Posted: June 18, 2013 Filed under: NetApp, Storage | Tags: default snap settings, default snapshot settings, default snapshots, snap settings, snapshot settings 2 CommentsSnapshots are enabled by default when a volume is created. They follow the schedule as seen from the CLI command snap sched: 0 2 6@8,12,16,20

and from the System Manager GUI. Note the default Snapshot Reserve is 5% and that the checkbox for Enable scheduled Snapshots is checked by default.
Chinwag with Mike Laverick (@Mike_Laverick)
Posted: June 11, 2013 Filed under: Tid-bits, VMware | Tags: chinwag, mike brown, virtual mike brown, virtually mike brown, VirtuallyMikeB Leave a commentI was honored recently by being invited by Mike Laverick to be a guest on his Chinwag. Now, I knew what *the* Chinwag was, but I honestly didn’t know *what* a chinwag was. I had to look it up. It’s basically a chat – makes sense, right? You can find it on Mike’s blog, here. Our chat is below.
I’d like to thank Mike wholeheartedly for thinking of me and giving me the “publicity” that comes with being a guest on his Chinwag. It was truly an honor to “meet” him, as virtual as it was. I look forward to meeting him in person one day.
Cisco Nexus Fibre Channel configuration template
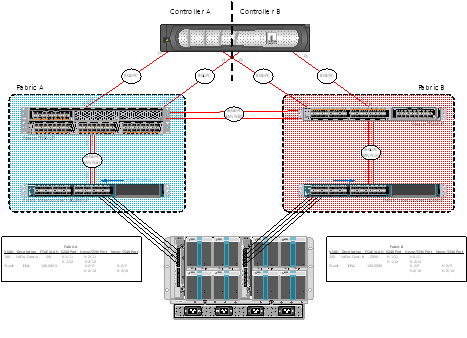
Posted: May 23, 2013 Filed under: Cisco Nexus, Networking, Storage | Tags: 5548up, 5596up, cisco nexus, cisco ucs, device-alias, eisl, e_port, fc, fc config, fc configuration, fc end host mode, fc switch mode, fc ucs, fibre channel, fibre channel configuration template, fibre channel template, f_port, isl, n_port, te_port, tf_port, ucs, vsan, zone, zoneset, zoning 6 CommentsI recently had the opportunity to configure native fibre channel in my test lab at work using Nexus 55xx series switches and Cisco’s UCS. What I’ll do in this post is to share my templatized fibre channel configuration in a somewhat ordered way, at least from the Nexus point of view. This test lab was configured with the attitude that it should show off the capabilities of the hardware and software. Concepts included in this initial configuration include NPIV, NPV, SAN port-channels, F_Port trunking, VSANs, device aliases, and of course, standard FC concepts like zones and zonesets.
Let me first share the end-state as of today, what I’ll call Phase I. I’ll explain what my initial plan was for Phase I and, after learning a bit more, what I plan to do for Phase II. Please feel free to correct me in the comments below – I made a lot of mistakes configuring this and I wouldn’t be surprised if there’re a few more in there.